Building an Agentic RAG System with Pinecone, Ollama & LangChain
Learn how to build an intelligent RAG system with agentic capabilities using Pinecone, Ollama, and LangChain

Introduction
In this tutorial, we'll build an Agentic Retrieval-Augmented Generation (RAG) system that integrates:
- Ollama for running LLMs locally
- LangChain for orchestration, retrieval, and agent tools
- Pinecone as a vector database for embeddings storage and retrieval
- Next.js frontend to interact with the agent
What you'll learn:
- Understanding embeddings and vector databases
- Setting up Ollama for local LLM inference
- Configuring Pinecone for vector storage
- Building an agentic RAG pipeline with LangChain
- Creating a FastAPI backend and Next.js frontend
What is Agentic RAG?
Traditional RAG = Retrieve (from knowledge base) + Generate (LLM response).
Agentic RAG adds reasoning + tool usage + memory. Instead of just retrieving text chunks, the agent can:
- Remember past user interactions (conversational memory)
- Use external tools (like Pinecone for retrieval)
- Synthesize answers using context and general knowledge
Agentic RAG vs Traditional RAG:
Traditional RAG simply retrieves and generates. Agentic RAG adds decision-making, tool usage, and memory to create more intelligent responses.
Project Structure
Before we start coding, let's set up the project structure:
agentic-rag/
├── backend/ # Python FastAPI backend
│ ├── main.py # FastAPI app entry point
│ ├── agent.py # LangChain agent setup
│ ├── ingest_docs.py # Document ingestion script
│ └── docs/ # Sample documents to ingest
│ └── intro_to_rag.txt
│
├── frontend/ # Next.js frontend
│ ├── src/
│ │ └── app/ # Next.js App Router
│ │ ├── page.tsx # Main chat UI
│ │ └── layout.tsx # Root layout
│ ├── package.json
│ └── next.config.js
│
├── .env # Environment variables
└── README.mdCreate separate folders for backend (Python) and frontend (Next.js) to keep the project organized.
Step 1: Setting up the Environment
- 1
Install Ollama on your system Create Python virtual environment Install Python dependencies Set up Next.js frontend Configure environment variables
Install Ollama
macOS / Linux:
curl -fsSL https://ollama.com/install.sh | shWindows:
Download the installer from Ollama Download Page, or run:
iwr https://ollama.com/download/OllamaSetup.exe -OutFile OllamaSetup.exe
Start-Process OllamaSetup.exeVerify installation and download the LLaMA 3 model:
ollama --version
ollama pull llama3.1Create Backend Project
mkdir agentic-rag
cd agentic-rag
mkdir backend frontend backenddocs
# Set up Python backend
cd backend
# --- Option 1: Virtualenv ---
python -m venv venv
# Activate virtual environment
source venv/bin/activate # (Linux/Mac)
venv\Scripts\activate # (Windows)
# --- Option 2: Conda ---
# Create conda environment
conda create -n agentic-rag python=3.11 -y
# Activate conda environment
conda activate agentic-ragInstall Python Dependencies
pip install langchain langchain-community pinecone tiktoken fastapi uvicorn python-dotenv pydantic langchain_pinecone langchain_ollamaCreate Frontend Project
cd ../frontend
npx create-next-app@latest . --typescript --tailwind --app
# Install additional dependencies
npm installConfigure Environment Variables
# Pinecone Configuration
PINECONE_API_KEY=your-pinecone-api-key-here
PINECONE_ENVIRONMENT=us-east-1
PINECONE_INDEX_NAME=rag-memory
# Ollama Configuration (if running remotely)
OLLAMA_BASE_URL=http://localhost:11434Never commit .env files to version control. Add it to .gitignore immediately!
Step 2: Understanding Embeddings
Embeddings are vector representations of text. Think of them as numerical fingerprints of meaning.
For example:
- "dog" → [0.12, -0.98, 0.33, …]
- "puppy" → [0.11, -1.01, 0.29, …]
Words/phrases with similar meanings will have embeddings that are close in vector space. This enables semantic search.
Why Embeddings Matter:
Embeddings capture semantic meaning, not just keyword matches. This means "automobile" and "car" will have similar vectors even though they're different words.
Step 3: Setting up Pinecone
- 1
Sign up at Pinecone.
- 2
Get your API key from the console.
- 3
Create an index with appropriate dimensions.
- 4
Connect to your index from Python.
Choose the correct dimension for your embedding model:
multilingual-e5-large: 1024 dimensions- Custom models: check documentation
We will be using is "multilingual-e5-large" hosted by Pinecone
Step 4: Document Ingestion Pipeline
Before the agent can answer questions, we need to ingest documents into Pinecone.
- 1
Load documents (PDF, TXT, Markdown, etc.) Split into smaller chunks Generate embeddings for each chunk Store embeddings in Pinecone
Create Sample Document
Retrieval-Augmented Generation (RAG) Overview
RAG is a technique that enhances large language models by providing them with relevant context from external knowledge sources. Instead of relying solely on the model's training data, RAG retrieves relevant information from a knowledge base and includes it in the prompt.
How RAG Works:
1. A user asks a question
2. The question is converted into an embedding (vector)
3. Similar embeddings are retrieved from a vector database
4. Retrieved documents are provided as context to the LLM
5. The LLM generates an answer based on the context
Benefits of RAG:
- Reduces hallucinations by grounding responses in real data
- Enables models to access up-to-date information
- Allows domain-specific knowledge without retraining
- More cost-effective than fine-tuning for many use cases
Agentic RAG takes this further by adding reasoning, memory, and tool usage capabilities.Document Loading and Chunking
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_pinecone import PineconeEmbeddings
from pinecone import Pinecone, ServerlessSpec
load_dotenv()
def ingest_documents():
"""Load, chunk, generate embeddings, and store in Pinecone"""
print("Loading documents...")
loader = DirectoryLoader("docs/", glob="**/*.txt", loader_cls=TextLoader)
documents = loader.load()
print(f"Loaded {len(documents)} documents")
print("Splitting documents into chunks...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
length_function=len
)
chunks = text_splitter.split_documents(documents)
print(f"Created {len(chunks)} chunks")
print("Initializing Pinecone client")
pinecone_api_key = os.environ.get("PINECONE_API_KEY")
pinecone_env = os.environ.get("PINECONE_ENVIRONMENT", "us-east-1-aws")
pinecone_index_name = os.environ.get("PINECONE_INDEX_NAME", "rag-memory")
model_name = "multilingual-e5-large"
# Create Pinecone instance
pc = Pinecone(api_key=pinecone_api_key)
# Create index if it doesn't exist
if not pc.has_index(pinecone_index_name):
pc.create_index_for_model(
name=pinecone_index_name,
cloud="aws",
region=pinecone_env,
embed={
"model":model_name,
"field_map":{"text": "chunk_text"}
})
print(f"Created Pinecone index: {pinecone_index_name}")
else:
print(f"Index {pinecone_index_name} already exists")
# Connect to the index
index = pc.Index(pinecone_index_name)
print("Generating embeddings")
embeddings = PineconeEmbeddings(
model=model_name,
pinecone_api_key=pinecone_api_key
)
print("Upserting chunks into Pinecone index")
vectors = embeddings.embed_documents([doc.page_content for doc in chunks])
upsert_data = [
{"id": str(i), "values": vec, "metadata": {"text": chunks[i].page_content}}
for i, vec in enumerate(vectors)
]
index.upsert(upsert_data)
print("Documents successfully embedded and stored in Pinecone!")
if __name__ == "__main__":
ingest_documents()Run the ingestion script:
python ingest_docs.pyYour documents are now embedded and stored in Pinecone, ready for semantic search!
Step 5: Building the LangChain Agent
Now let's create the core agent that combines retrieval, LLM reasoning, and memory.
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage
from langchain_pinecone import PineconeVectorStore, PineconeEmbeddings
from langchain_ollama import OllamaLLM
from operator import itemgetter
from typing import Dict, List, Literal
import re
load_dotenv()
# Query type definitions
QueryType = Literal["GREETING", "FAREWELL", "CASUAL", "KNOWLEDGE", "FOLLOWUP"]
# Template constants
ROUTER_TEMPLATE = """Classify this query into ONE category:
GREETING: hi, hello, hey, greetings
FAREWELL: bye, goodbye, see you, farewell
CASUAL: how are you, what's up, who are you, what can you do, tell me about yourself, introduce yourself
KNOWLEDGE: specific factual questions about topics, domains, or information in knowledge base
FOLLOWUP: references to previous conversation (tell me more, explain that, what about...)
Query: {question}
Return ONLY ONE WORD - the category name:"""
RAG_TEMPLATE = """You are a helpful AI assistant. Your name is AIDev. Answer questions naturally. If provided context is relevant, use it. If not, use your general knowledge. Never mention the retrieval process or context availability.
IMPORTANT RULES:
1. First, check if the provided context is relevant to the question
2. If context is relevant and helpful: Use it to answer
3. If context is NOT relevant or unhelpful: Use your general knowledge to answer
4. Be direct and concise (2-4 sentences)
5. Don't mention the context or retrieval process - just answer naturally
Retrieved Context:
{context}
Question: {question}"""
# Static responses
RESPONSES = {
"GREETING_NEW": "Hello! I'm here to answer your questions. What would you like to know?",
"GREETING_RETURN": "Hello! How can I help you?",
"FAREWELL": "Goodbye! Feel free to return if you have more questions.",
"WHO_ARE_YOU": "I'm an AI assistant designed to help answer your questions using a knowledge base. I can have casual conversations and provide detailed information on topics I've been trained on. How can I assist you today?",
"ERROR": "I'm sorry, I encountered an issue. Could you try rephrasing?"
}
class AgenticRAG:
"""Optimized agentic RAG with LangChain runnables."""
def __init__(self):
# Load configuration
self.pinecone_api_key = os.getenv("PINECONE_API_KEY")
self.pinecone_index_name = os.getenv("PINECONE_INDEX_NAME", "rag-memory")
self.ollama_base_url = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434")
# Initialize components
self._init_vectorstore()
self._init_llms()
self._init_chains()
# Chat history storage
self.store: Dict[str, InMemoryChatMessageHistory] = {}
print("Optimized Agentic RAG initialized!")
def _init_vectorstore(self):
"""Initialize embeddings and vectorstore."""
self.embeddings = PineconeEmbeddings(
model="multilingual-e5-large",
pinecone_api_key=self.pinecone_api_key,
)
self.vectorstore = PineconeVectorStore(
embedding=self.embeddings,
index_name=self.pinecone_index_name,
text_key="text",
)
self.retriever = self.vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4},
)
def _init_llms(self):
"""Initialize LLM instances."""
base_config = {
"model": "llama3.1",
"base_url": self.ollama_base_url,
}
self.llm = OllamaLLM(**base_config, temperature=0.3)
self.router_llm = OllamaLLM(**base_config, temperature=0.0)
def _init_chains(self):
"""Build runnable chains."""
# Router chain
self.router_chain = (
ChatPromptTemplate.from_template(ROUTER_TEMPLATE)
| self.router_llm
| StrOutputParser()
)
# Casual chat chain
casual_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Your name is AIDev. Keep responses brief and natural."),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}")
])
self.casual_chain = RunnableWithMessageHistory(
casual_prompt | self.llm | StrOutputParser(),
self._get_session_history,
input_messages_key="question",
history_messages_key="chat_history",
)
# RAG chain
rag_prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI assistant. Your name is AIDev. Answer questions naturally. If provided context is relevant, use it. If not, use your general knowledge. Never mention the retrieval process or context availability."),
MessagesPlaceholder(variable_name="chat_history"),
("human", RAG_TEMPLATE)
])
self.rag_chain = RunnableWithMessageHistory(
{
"context": itemgetter("question") | self.retriever | self._format_docs,
"question": itemgetter("question"),
"chat_history": itemgetter("chat_history"),
}
| rag_prompt
| self.llm
| StrOutputParser(),
self._get_session_history,
input_messages_key="question",
history_messages_key="chat_history",
output_messages_key="output",
)
@staticmethod
def _format_docs(docs) -> str:
"""Format documents for context."""
return "\n\n".join(doc.page_content for doc in docs)
def _get_session_history(self, session_id: str) -> BaseChatMessageHistory:
"""Get or create chat history for a session."""
if session_id not in self.store:
self.store[session_id] = InMemoryChatMessageHistory()
return self.store[session_id]
def _classify_query(self, question: str) -> QueryType:
"""Classify query type using LLM - supports all languages and variations."""
try:
classification = self.router_chain.invoke({"question": question}).strip().upper()
match = re.search(r"(GREETING|FAREWELL|CASUAL|KNOWLEDGE|FOLLOWUP)", classification)
qtype = match.group(1) if match else "KNOWLEDGE"
# Match first valid category
for qtype in ["GREETING", "FAREWELL", "CASUAL", "KNOWLEDGE", "FOLLOWUP"]:
if qtype in classification:
print(f"Query classified as: {qtype}")
return qtype
print("Query classified as: KNOWLEDGE (default)")
return "KNOWLEDGE"
except Exception as e:
print(f"Classification error: {e}, defaulting to KNOWLEDGE")
return "KNOWLEDGE"
def _is_meaningless_input(self, question: str) -> bool:
"""Check if input is meaningless (just punctuation, numbers, or very short)."""
# Remove whitespace
cleaned = question.strip()
# Empty or just whitespace
if not cleaned:
return True
# Only punctuation/symbols
if all(c in '.,;:!?-_=+[]{}()|/#$%^&*"' for c in cleaned):
return True
# Only numbers
if cleaned.replace('.', '').replace(',', '').isdigit():
return True
# Single character (except valid single-char queries in some languages)
if len(cleaned) == 1 and not cleaned.isalpha():
return True
return False
def _add_to_history(self, session_id: str, user_msg: str, ai_msg: str):
"""Add messages to history."""
history = self._get_session_history(session_id)
history.add_user_message(user_msg)
history.add_ai_message(ai_msg)
def _create_response(self, answer: str, query_type: QueryType, sources: List[str] = None, source_count: int = 0) -> Dict:
"""Create standardized response."""
return {
"answer": answer,
"sources": sources or [],
"query_type": query_type,
**({"source_count": source_count} if source_count else {})
}
def _handle_greeting(self, session_id: str) -> Dict:
"""Handle greeting."""
history = self._get_session_history(session_id)
response = RESPONSES["GREETING_RETURN"] if history.messages else RESPONSES["GREETING_NEW"]
self._add_to_history(session_id, "greeting", response)
return self._create_response(response, "GREETING")
def _handle_farewell(self, session_id: str) -> Dict:
"""Handle farewell."""
self._add_to_history(session_id, "farewell", RESPONSES["FAREWELL"])
return self._create_response(RESPONSES["FAREWELL"], "FAREWELL")
def _handle_casual(self, question: str, session_id: str) -> Dict:
"""Handle casual chat."""
try:
response = self.casual_chain.invoke(
{"question": question},
config={"configurable": {"session_id": session_id}}
)
return self._create_response(response, "CASUAL")
except Exception as e:
print(f"Casual chat error: {e}")
return self._create_response("I'm doing well, thanks! How can I help you?", "CASUAL")
def _handle_knowledge(self, question: str, session_id: str) -> Dict:
"""Handle knowledge queries with RAG + fallback to general knowledge."""
try:
docs = self.retriever.invoke(question)
# Check if we got any relevant docs (optional relevance filtering)
context_available = bool(docs)
response = self.rag_chain.invoke(
{"question": question},
config={"configurable": {"session_id": session_id}}
)
sources = [
doc.page_content[:200] + "..." if len(doc.page_content) > 200 else doc.page_content
for doc in docs
] if context_available else []
return self._create_response(
response,
"KNOWLEDGE",
sources,
len(docs) if context_available else 0
)
except Exception as e:
print(f"RAG query error: {e}")
return self._create_response(RESPONSES["ERROR"], "KNOWLEDGE")
def query(self, question: str, session_id: str = "default") -> Dict:
"""
Main query method with intelligent routing.
Args:
question: User's question
session_id: Session identifier for conversation history
Returns:
Dict with answer, sources, and metadata
"""
if not question or not question.strip():
raise ValueError("Query cannot be empty")
question = question.strip()
query_type = self._classify_query(question)
# Route to handler
handlers = {
"GREETING": self._handle_greeting,
"FAREWELL": self._handle_farewell,
"CASUAL": self._handle_casual,
}
handler = handlers.get(query_type)
return handler(session_id) if query_type in ["GREETING", "FAREWELL"] else handler(question, session_id) if handler else self._handle_knowledge(question, session_id)
def get_history(self, session_id: str = "default") -> List[Dict]:
"""Get conversation history for a session."""
history = self._get_session_history(session_id)
return [
{"role": "human" if isinstance(msg, HumanMessage) else "ai", "content": msg.content}
for msg in history.messages
]
def get_memory_summary(self, session_id: str = "default") -> str:
"""Get summary of conversation."""
history = self._get_session_history(session_id)
return f"Session '{session_id}' has {len(history.messages)} messages." if history.messages else "No conversation history yet."
def reset_memory(self, session_id: str = "default"):
"""Clear conversation memory for a session."""
self.store.pop(session_id, None)
print(f"🗑 Memory cleared for session: {session_id}")
def list_sessions(self) -> List[str]:
"""List all active sessions."""
return list(self.store.keys())
def show_last_exchange(self, session_id: str = "default"):
"""Show last exchange."""
history = self._get_session_history(session_id)
if len(history.messages) >= 2:
print(f"\nLast exchange:")
print(f"You: {history.messages[-2].content}")
print(f"Me: {history.messages[-1].content}")
else:
print("No previous exchange yet.")
# Global agent instance
agent = AgenticRAG()Step 6: FastAPI Backend
Create a REST API to expose the agent to the frontend.
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from agent import agent
import uvicorn
app = FastAPI(title="Agentic RAG API")
# Configure CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class QueryRequest(BaseModel):
query: str
class QueryResponse(BaseModel):
answer: str
sources: list[str]
@app.get("/")
def root():
return {"message": "Agentic RAG API is running"}
@app.post("/chat", response_model=QueryResponse)
async def chat(request: QueryRequest):
"""Chat endpoint for querying the agent"""
try:
if not request.query.strip():
raise HTTPException(status_code=400, detail="Query cannot be empty")
result = agent.query(request.query)
return QueryResponse(
answer=result["answer"],
sources=result["sources"]
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)Run the backend:
python main.pyTest the API:
# In a new terminal
curl -X POST http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{"query": "What is RAG?"}'Step 7: Next.js Frontend
Create an interactive chat interface.
"use client";
import { useState, useEffect, useRef } from "react";
interface Message {
role: "user" | "assistant" | "error";
content: string;
sources?: string[];
}
export default function ChatPage() {
const [messages, setMessages] = useState<Message[]>([]);
const [input, setInput] = useState("");
const [isLoading, setIsLoading] = useState(false);
const chatBoxRef = useRef<HTMLDivElement | null>(null);
const inputRef = useRef<HTMLTextAreaElement | null>(null);
// Send message
const sendMessage = async () => {
const text = input.trim();
if (!text || isLoading) return;
const userMsg: Message = { role: "user", content: text };
setMessages((prev) => [...prev, userMsg]);
setInput("");
setIsLoading(true);
try {
const res = await fetch("http://localhost:8000/chat", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query: text }),
});
if (!res.ok) throw new Error(`API error: ${res.status}`);
const data = await res.json();
setMessages((prev) => [
...prev,
{ role: "assistant", content: data.answer, sources: data.sources },
]);
} catch (error) {
console.error("Chat API Error:", error);
setMessages((prev) => [
...prev,
{ role: "error", content: "Error: Could not connect to backend." },
]);
} finally {
setIsLoading(false);
requestAnimationFrame(() => {
inputRef.current?.focus();
});
}
};
// Auto-scroll when messages change
useEffect(() => {
if (chatBoxRef.current) {
chatBoxRef.current.scrollTop = chatBoxRef.current.scrollHeight;
}
}, [messages, isLoading]);
useEffect(() => {
const ta = inputRef.current;
if (!ta) return;
ta.style.height = "auto";
ta.style.height = `${ta.scrollHeight}px`;
}, [input]);
useEffect(() => {
inputRef.current?.focus();
}, []);
const handleKeyDown = (e: React.KeyboardEvent<HTMLTextAreaElement>) => {
if (e.key === "Enter" && !e.shiftKey) {
e.preventDefault();
sendMessage();
}
};
return (
<div className="flex flex-col h-screen bg-gray-950 text-gray-100 antialiased">
{/* Header */}
<header className="w-full bg-gray-900 p-4 border-b border-gray-800 shadow-lg">
<div className="max-w-2xl mx-auto text-center">
<h1 className="text-2xl font-semibold text-cyan-400">AI Chatbot</h1>
</div>
</header>
{/* Chat Area */}
<main className="flex-1 overflow-hidden max-w-2xl mx-auto w-full p-4">
<div
ref={chatBoxRef}
className="chat-scroll h-full overflow-y-auto flex flex-col space-y-4 pb-6"
style={{
msOverflowStyle: "none",
scrollbarWidth: "none",
}}
>
{messages.length === 0 && !isLoading && (
<div className="flex-1 flex items-center justify-center text-center">
<p className="text-gray-400 text-sm">
Ask me anything! I'll answer using my knowledge base.
</p>
</div>
)}
{messages.map((m, i) => (
<MessageBubble key={i} {...m} />
))}
{isLoading && <TypingIndicator />}
</div>
<style jsx>{`
.chat-scroll::-webkit-scrollbar {
display: none;
}
`}</style>
</main>
{/* Input Bar */}
<footer className="bg-gray-900 p-4 border-t border-gray-800 shadow-[0_-5px_15px_rgba(0,0,0,0.5)]">
<div className="flex gap-3 max-w-2xl mx-auto">
<textarea
ref={inputRef}
rows={1}
value={input}
onChange={(e) => setInput(e.target.value)}
onKeyDown={handleKeyDown}
placeholder={isLoading ? "AI is typing..." : "Type a message..."}
disabled={isLoading}
className="flex-1 p-3 rounded-xl bg-gray-800 border border-gray-700 text-gray-100 placeholder-gray-400 focus:ring-2 focus:ring-cyan-500 focus:outline-none transition resize-none overflow-hidden text-sm"
/>
<button
onClick={sendMessage}
disabled={!input.trim() || isLoading}
className={`px-6 py-3 rounded-xl font-medium shadow-lg transition duration-200 ease-in-out ${
!input.trim() || isLoading
? "bg-gray-700 text-gray-500 cursor-not-allowed opacity-70"
: "bg-cyan-600 hover:bg-cyan-500 text-white transform hover:scale-[1.02] active:scale-[0.98]"
}`}
>
{isLoading ? "..." : "Send"}
</button>
</div>
</footer>
</div>
);
}
// --- Chat Bubbles ---
const MessageBubble = ({
role,
content,
sources,
}: {
role: string;
content: string;
sources?: string[];
}) => {
const isUser = role === "user";
const isError = role === "error";
let bubbleClasses = "";
let alignment = isUser ? "self-end" : "self-start";
if (isUser) {
bubbleClasses =
"bg-cyan-700 text-white rounded-br-md shadow-lg shadow-cyan-900/40";
} else if (isError) {
bubbleClasses =
"bg-red-900 text-red-200 border border-red-700 shadow-lg shadow-red-950/50";
} else {
bubbleClasses =
"bg-gray-800 text-gray-100 rounded-tl-md border border-gray-700 shadow-lg shadow-gray-900/50";
}
return (
<div className={`flex ${alignment} max-w-xs md:max-w-md lg:max-w-lg`}>
<div
className={`p-3 rounded-2xl whitespace-pre-wrap ${bubbleClasses} text-sm`}
>
{!isUser && (
<strong
className={`font-semibold capitalize block mb-1 text-xs ${
isError ? "text-red-300" : "text-cyan-400"
}`}
>
{role}:
</strong>
)}
{content}
{/* Sources */}
{sources && sources.length > 0 && (
<details className="mt-2 text-xs opacity-80">
<summary className="cursor-pointer hover:opacity-100">
View Sources ({sources.length})
</summary>
<div className="mt-2 space-y-2">
{sources.map((src, idx) => (
<div
key={idx}
className="bg-gray-900 p-2 rounded border border-gray-700 text-gray-400"
>
{src}
</div>
))}
</div>
</details>
)}
</div>
</div>
);
};
const TypingIndicator = () => (
<div className="flex self-start max-w-xs md:max-w-md lg:max-w-lg">
<div className="bg-gray-800 px-4 py-3 rounded-2xl rounded-tl-md border border-gray-700 shadow-lg shadow-gray-900/50">
<div className="flex space-x-1.5 items-center">
<span
className="w-2 h-2 bg-cyan-400 rounded-full animate-bounce-dot"
style={{ animationDelay: "0s" }}
></span>
<span
className="w-2 h-2 bg-cyan-400 rounded-full animate-bounce-dot"
style={{ animationDelay: "0.15s" }}
></span>
<span
className="w-2 h-2 bg-cyan-400 rounded-full animate-bounce-dot"
style={{ animationDelay: "0.3s" }}
></span>
</div>
</div>
<style jsx global>{`
@keyframes bounce-dot {
0%,
80%,
100% {
transform: scale(0);
}
40% {
transform: scale(1);
}
}
.animate-bounce-dot {
animation: bounce-dot 1.4s infinite ease-in-out both;
}
`}</style>
</div>
);Run the frontend:
cd frontend
npm run devOpen http://localhost:3000 to see your chat interface!
Demo Preview
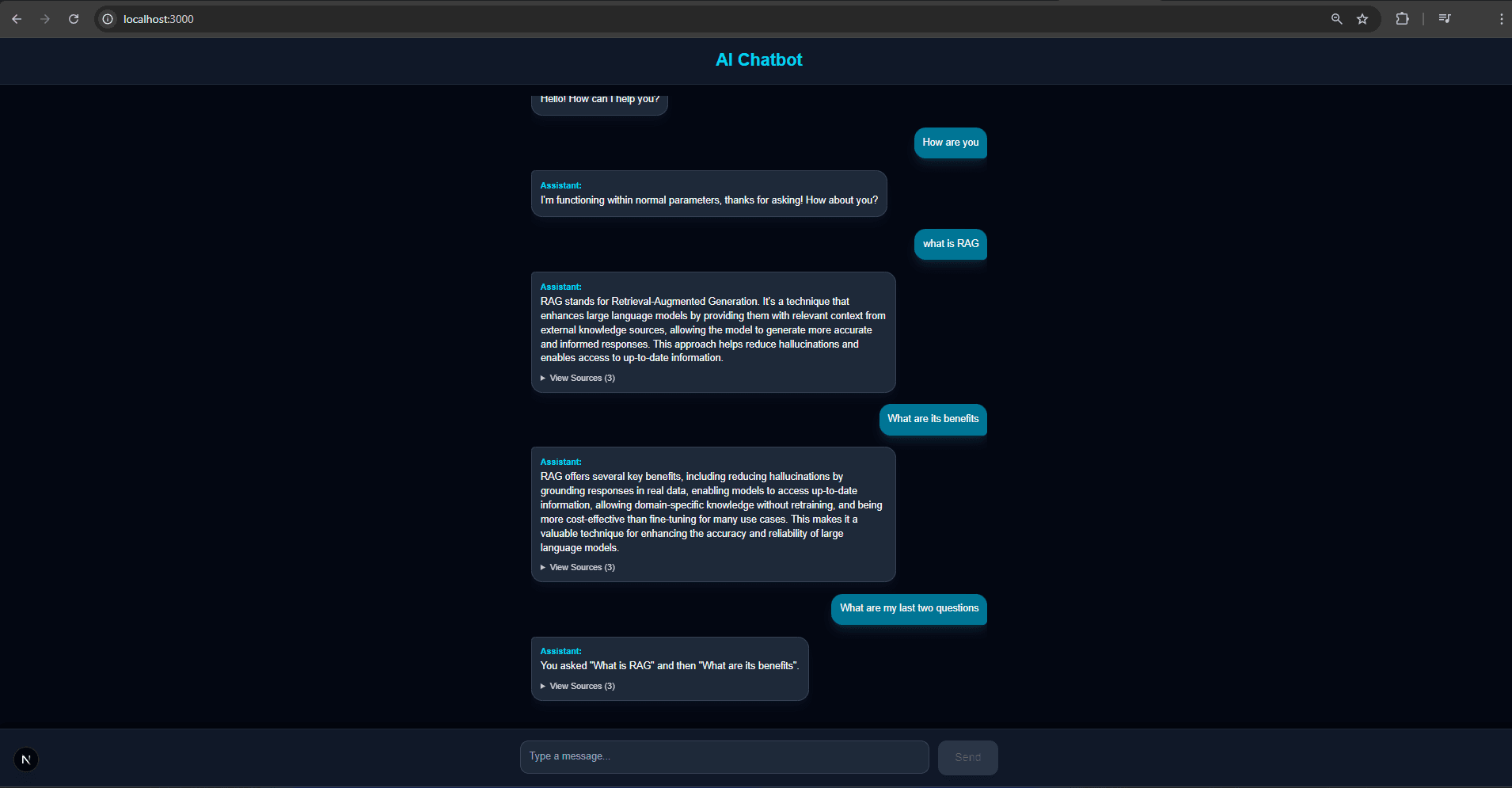
Chat interface
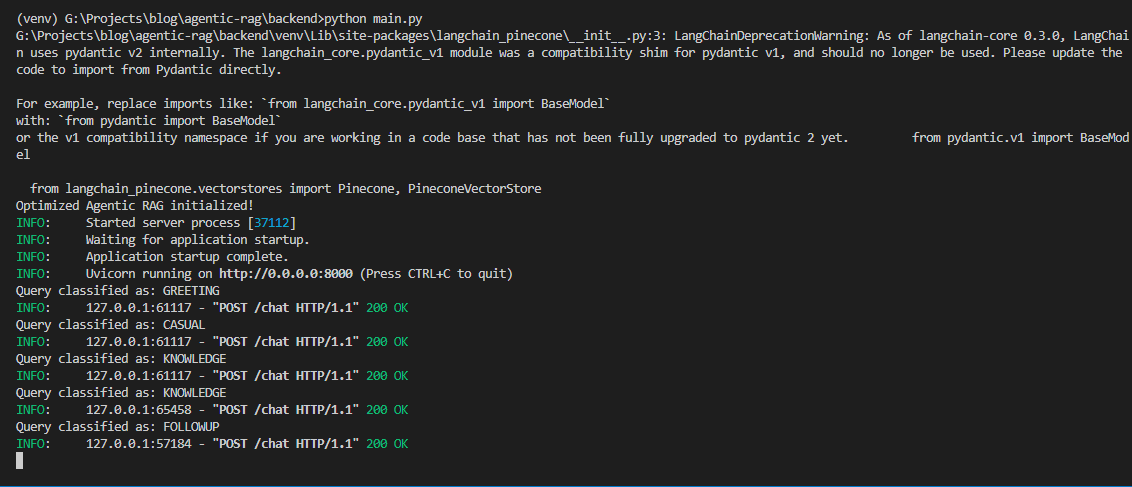
FastAPI backend
Knowledge Check
What does Pinecone store in this RAG setup?
Why use embeddings instead of keyword search?
System Architecture
Next Steps
🎉 Congratulations! You've built a full Agentic RAG pipeline with memory, reasoning, and semantic retrieval.
Ideas to extend your system:
Troubleshooting
Additional Resources
Project Links
Learn More:
Key Takeaways
You've successfully built an end-to-end Agentic RAG system that:
- Uses Ollama for local LLM inference
- Stores document embeddings in Pinecone for fast semantic search
- Leverages LangChain for orchestration and memory management
- Provides a clean FastAPI backend and Next.js frontend
You now have the foundation to build intelligent AI applications that can answer questions based on your own documents with contextual awareness and memory!
